Trie 是一種樹狀結構,可以用來在大量字串中快速搜尋某個字串。當然這樣問題也可以用 hash table 來解決,但是 Trie 在解決以下問題上有其優勢,
- 找出每個有特定 prefix 的字串
- 按照字典順序列出所有字串
hash table 面對上述問題,有兩個缺點
- 如果 input 大部份都擁有一樣的 prefix ,hash table 相對 trie 會耗費較多記憶體空間。
- hash table 可能發生碰撞,導致搜尋的 time complexity 高達 O (n) ,n 是總共插入的資料數量; 而 Trie 執行搜尋可以保持時間複雜度僅有 O (k),k 是搜尋字串的長度。
Trie 樹利用字串之間的共同前綴,將重複的前綴放在同一條路徑上,即可畫出如下圖的樹狀架構。
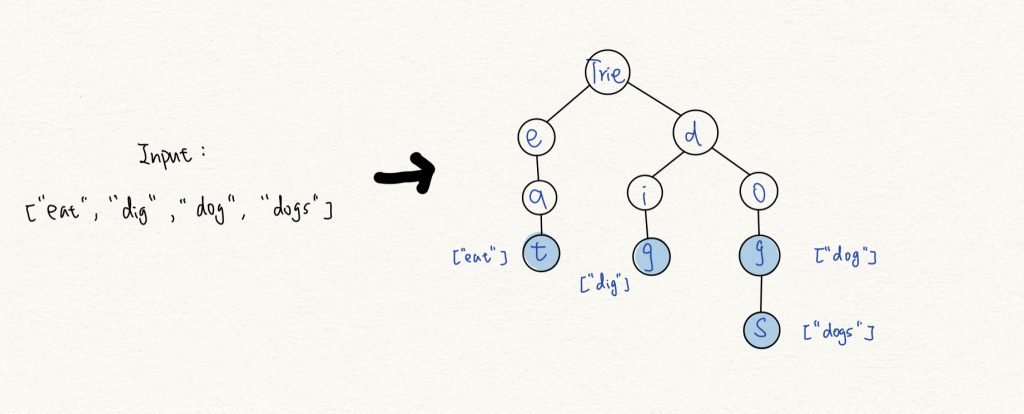
Trie 在現實生活中的應用相當常見,像是搜尋引擎的關鍵字建議或是 word 上的錯誤字訂正。
一般 Trie 資料結構會實現以下三個方法:
- insert(word) : 插入一個新的字串。
- search(word) : 尋找一個字串。
- startWith(value) : 在 trie 內是否存在值為 value 的前綴。
以下來看兩題 Leetcode 範例:
Leetcode #208 Implement a Trie
- Trie 的 root 是不含資料
- 每個 node 都包含一個 boolean 變數
isEndOfWord,紀錄該 node 是不是一個單字的結尾。
方法 1
- 有 constructor 和 Destructor ,該題討論區很多解答都沒有完整的這樣寫。
- 題目有說字串組成只包含小寫英文,可以直接透過 vector 劃分好大小。
class Trie {
public:
/** Initialize your data structure here. */
Trie() {
root = new TrieNode();
}
/** Inserts a word into the trie. */
void insert(string word) {
TrieNode *curr = root;
for (auto ch:word)
{
if (curr->children[ch-'a'] == nullptr)
{
struct TrieNode *newNode = new TrieNode();
curr->children[ch-'a'] = newNode;
}
curr = curr->children[ch-'a'];
}
curr->isEndOfWord = true;
}
/** Returns if the word is in the trie. */
bool search(string word) {
TrieNode *curr = root;
for (auto ch:word)
{
if (curr->children[ch-'a'] == nullptr)
return false;
curr = curr->children[ch-'a'];
}
return curr->isEndOfWord;
}
/**
* Returns if there is any word in the trie
* that starts with the given prefix.
*/
bool startsWith(string prefix) {
TrieNode *curr = root;
for (auto ch:prefix)
{
if (curr->children[ch-'a'] == nullptr)
return false;
curr = curr->children[ch-'a'];
}
return true;
}
private:
struct TrieNode {
bool isEndOfWord;
vector<TrieNode*> children;
TrieNode() {
isEndOfWord = false;
children = vector<TrieNode*>(26, nullptr);
}
~TrieNode() {
for (auto child:children)
{
if (child) delete child;
}
}
};
struct TrieNode *root;
};方法 2 Hash Table
- 如果節點內的資料只包含英文字母,當然採取方法 1 的 array 即可,但如果不僅限於單純英文字母,那採用 Hash table (以 c++ 來說,採用 unordered_map) 來維護可能的 child node 比較適合。
class Trie {
public:
/** Initialize your data structure here. */
Trie() {
root = new TrieNode();
}
/** Inserts a word into the trie. */
void insert(string word) {
TrieNode *curr = root;
for (auto ch:word)
{
if (!curr->children.count(ch))
{
struct TrieNode *newNode = new TrieNode();
curr->children[ch] = newNode;
}
curr = curr->children[ch];
}
curr->isEndOfWord = true;
}
/** Returns if the word is in the trie. */
bool search(string word) {
TrieNode *curr = root;
for (auto ch:word)
{
if (!curr->children.count(ch))
return false;
curr = curr->children[ch];
}
return curr->isEndOfWord;
}
/**
* Returns if there is any word in the trie
* that starts with the given prefix.
*/
bool startsWith(string prefix) {
TrieNode *curr = root;
for (auto ch:prefix)
{
if (!curr->children.count(ch))
return false;
curr = curr->children[ch];
}
return true;
}
private:
struct TrieNode {
bool isEndOfWord;
unordered_map<char, TrieNode*> children;
TrieNode() {
isEndOfWord = false;
}
~TrieNode() {
for (auto child:children)
{
if (child.second) delete child.second;
}
}
};
TrieNode *root;
};Leetcode #211 Design Add and Search Words Data Structure
這題為上一題的延伸,差別在於要處理特殊字元 '.' 。
方法 1 遞迴法
採取遞迴方式來 traverse 資料結構 Trie ,你也可以理解成是透過 DFS 來 traverse Trie 。
如果是遇到 '.' 這個特殊字元,所有存在的 node 都符合要求,都需要再往下做 DFS 。
class WordDictionary {
struct TrieNode {
bool isEndOfWord;
unordered_map<char, TrieNode*> children;
TrieNode () : isEndOfWord(false) { }
~TrieNode () {
for (auto child:children)
{
if (child.second) delete child.second;
}
}
};
TrieNode *root = nullptr;
public:
/** Initialize your data structure here. */
WordDictionary() {
root = new TrieNode ();
}
void addWord(string word) {
TrieNode *curr = root;
for (auto &ch:word)
{
if (curr->children.find(ch) == curr->children.end())
{
TrieNode *newNode = new TrieNode();
curr->children[ch] = newNode;
}
curr = curr->children[ch];
}
curr->isEndOfWord = true;
}
bool search(string word) {
return searchWord (0, word, root);
}
bool searchWord (int idx, string& word, TrieNode *curr)
{
if (idx == word.size())
return curr->isEndOfWord;
if (word[idx] == '.') {
for (auto it=curr->children.begin(); it != curr->children.end(); it++) {
if (searchWord(idx+1, word, it->second))
return true;
}
} else if (curr->children.find(word[idx]) != curr->children.end())
return searchWord(idx+1, word, curr->children[word[idx]]);
return false;
}
};Reference
Updated on 2023-01-29 06:09:53 星期日